
Tokenization is a necessary and often overlooked component in large language models (LLMs). While often discussed in the context of text processing, tokenization represents a deeper paradigm of transforming information into discrete units of representation. In this post, we will explore the importance of tokenization and how it might very well be the key to unlocking the advanced abilities of what we expect AI to be in the future
To get a bit sci-fi, understanding tokenization is like taking the red pill in The Matrix - it reveals the fundamental reality of how LLMs, the models that some believe to be the path to superintelligent AIs, truly perceive and process reality. Just as how The Matrix reduced the complex human experience and the world into streams of digital code, tokenization breaks down our continuous world into discrete, digestible pieces. And much like how those cascading green symbols represented everything from conversations to actions, tokens build a view that AI systems understand and interact with.
Okay, enough with the movie references. Let’s dive into why one should care about tokenization.
LLMs are sequential token predictors.
At its core, LLMs are trained to do one thing well: predict the next token given a sequence of tokens. While we commonly think of LLMs as predicting the next word in a sentence, the model does not really see words. This is probably why the number of r’s in strawberry is not really a setup suitable for an LLM if the tokenization doesn’t break down each character into a token. The same goes for any task where there is a discrepancy between the token representation and the problem solution expected from the model.
 This presents an interesting view, where instead of viewing LLMs as text processors, it is better to think of them as processing, possibly arbitrary, sequence of representations (let’s call them nodes) into the next representation in the sequence, i.e., the next node in the directed path. Fun fact: The idea of attention and transformers was, in fact, born out of this view, where the model is learning a graph of relationships between nodes.
This presents an interesting view, where instead of viewing LLMs as text processors, it is better to think of them as processing, possibly arbitrary, sequence of representations (let’s call them nodes) into the next representation in the sequence, i.e., the next node in the directed path. Fun fact: The idea of attention and transformers was, in fact, born out of this view, where the model is learning a graph of relationships between nodes.
Cool! So what’s the deal? Recently, there has been a surge of successful generative models that have applied the LLM architecture to generate audio, images, and videos. See Figure below for an example of one such generative model, VideoPoet. These generative models are not to be confused with the successes of diffusion models such as Stable Diffusion. VideoPoet presents a vision and audio token-only based language models that generate coherent multimodal outputs. The reason for this shift towards LLM multimodality, apart from the fact that you can represent diverse tasks into a single model, lies in the fact that infrastructure and optimization developed at scale to train LLMs can be easily reused. However, unlike text where tokenization with encoding schemes in a lossless, lookup manner was readily available, other modalities do not have such a clear path. This bottleneck highlights the importance of tokenization.
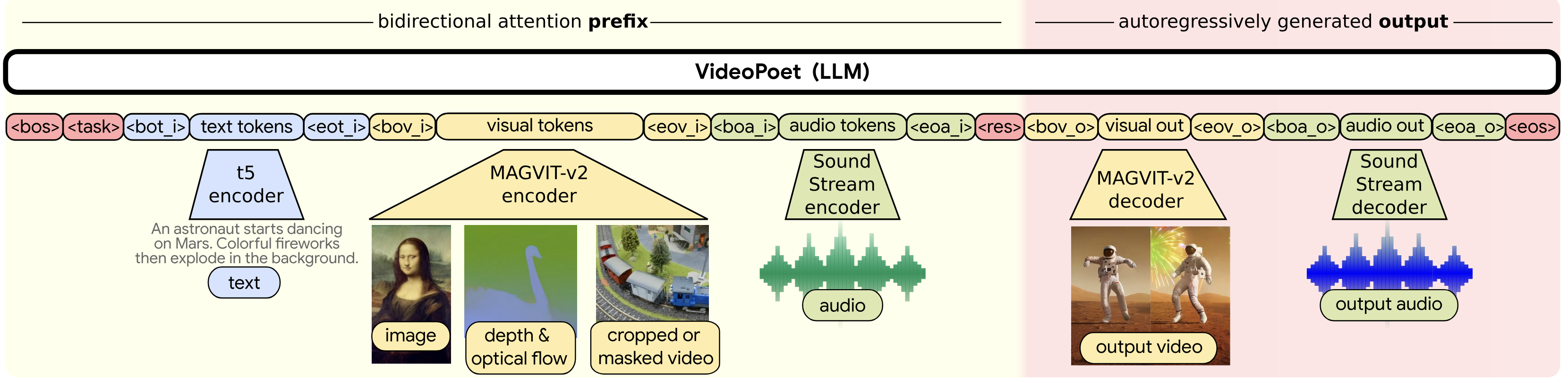
There is one detail that we left in the above picture, which is where the “sequence order” comes into play. Tokenization is inherently order-independent. Remember the graph of nodes? Nodes in a graph typically do not have order. This is one of the pros of graph representation – order independence and the ability to represent any relationship and entity with nodes and edges. We digress. LLMs integrate the order of input sequence tokens separately using a separate positional encoding. Whether this is a factor that we need to incorporate in representation and LLMs for all modalities is an open question for future models.
Why exisiting lossless encoding techniques are not sufficient?
We will use images as an example to observe this point, but similar arguments can be made for other modalities. What is the requirement? An image compression scheme where the image can be represented
- compactly (using one token per pixel quickly blows up the compute required to process even a modest size image),
- without any loss of important information (lossy representation might result in an inaccurate representation of input for an LLM) and
- in a dictionary lookup like manner, i.e., each image or patch in an image can be uniquely identified by a single element in a dictionary (collection of elements).
The combination of the above is a bit of an off ramp from traditional image encoding schemes. Conventionally, image compression schemes focus on the size of the dictionary as a larger dictionary would mean more bits (the index to the dictionary, the dictionary itself requires additional bits) to be spent per patch/image. Moreover, the dictionary itself is often adapted to the input image and is passed along with the image. This is in contrast to tokenization, where the dictionary is fixed but can be large. Note that having an overly large dictionary increases the complexity of training as LLMs now have to learn associations between a lot more discrete units, requiring even bigger training datasets.
Current approaches to tokenization in images focus on (1) and (3) above, where the image is divided into patches, encoded into features using a trained neural network, vector quantized, and decoded from features using a decoder neural network. A point to note here is having a better reconstruction loss in the encoding-decoding process does not necessarily mean the representation is better for LLMs, in particular, for generation. A thing that has puzzled me for a while is the part where approaches today go from features to tokens only to go back to embeddings. Hopefully, future works will shed light and provide a way forward. Moreover, current approaches focus on image patches of fixed size, which essentially means the models associate the same number of tokens for busy images as well as ones where the content is mostly empty.
Looking Forward
Vocabulary Design Finding the optimal vocabulary size and composition is an open problem. If it is too small, the model loses expressiveness; if it is too large, it becomes computationally inefficient. Moreover, there is no uncertainty in the tokenization process. Today, even the tokens “generated” are fed back to the LLM with no uncertainty for the next token prediction. Any forward pass through the LLM creates a prediction for all tokens in the sequence – This would mean that tokens generated with uncertainty can be corrected in a later path if a model is mistaken in its previous prediction. However, the training process (pre or post-training) might get tricky and is something that needs to be explored.
Cross-Modal Tokenization Another area of research that is largely unexplored is interpretability in a multi-modal tokenization process. Unlike text, where we are able to look back at tokenization to identify odd behaviors, tokenization in other modalities remains uninterpretable. This makes debugging models unachievable. For example, truly native voice agents are a bit of an unknown right now since any amount of guardrails, processing, and routing still relies on text transcription in an asynchronous manner. Understanding the tokenization in multimodal systems and the overlap in the token embedding space could be a key unlock for making the training process less data-hungry and more efficient.
Dynamic Tokenization The next frontier lies in developing more adaptive and dynamic tokenization approaches that can seamlessly handle all inputs. This will be crucial as we push towards more general artificial intelligence systems. Moving completely away from tokenization and working completely in an embedding space is desirable, but the discreteness of tokens probably offers flexibility in associations with less intensive training.
End-to-End Tokenization Another point to be made is the complete obliviousness of the model to the tokenization process. Unlike prompting, where the suggestions have all been around putting every detail in the input, the training of the model is completely agnostic to the tokenization process. The model is not really end-to-end, as tokenization is almost like a preprocessing step in the process.
Takeaways
Tokenization isn’t just a technical detail in today’s AI systems - it’s a fundamental step for discretizing and processing information. As we build more sophisticated AI systems, understanding these representation units becomes increasingly critical for both theoretical advances and practical applications.
The path to super AI systems is still filled with gaps, and tokenization is one that hasn’t made significant progress. The domain of compression and coding theory has a lot to offer, and we may see a revamped interest in the context of LLMs.